
OFFLINE SPEECH RECOGNITION
Introduction
Most businesses in the world try to reach their customers according to their culture to get customers more interact with the business. In that case, reaching the customers with their language is an excellent method to deal with their customers. Therefore, recognizing the customer’s indentation using their language is very important. Therefore, here, we’re mainly focusing on the “What is speech recognition?”, options we have to do speech recognition and speech recognition with English and Arabic languages. But we’ll provide enough guidance to switch to other languages easily.
Natural Language Processing (NLP) is the core of speech recognition. It’s like teaching a language to a small child. We train a model on how to use language and say what the rules of the language are by providing sample data, and the model starts learning after that we can get predictions utilizing that model. NLP is a trending machine learning application that is used in different areas to give a better experience to people in the world.
Let’s start with the content…!
Speech Recognition
Lots of speech recognition services are available on the internet as online services. As an example,
- Microsoft Azure Cognitive Services – Speech Recognition
- Google Cloud – Speech-to-text
( Documentation: Azure Speech Recognition, Google-speech-to-text ) can be considered a huge platform where we can perform speech recognition, and they are very accurate when producing their predictions. Majorly some organizations are messed with the cost that they have to pay for these services, some organizations don’t have cloud subscriptions, and some do not like to use cloud platforms as they do not like to share their business data with third parties since they are more sensitive data in the business. At this point, organizations looking for applications that can run in offline mode, connecting our model. However, some cases it is not important whether it uses the internet or not.
Okay, Let’s demonstrate some speech recognition methods that we can do offline.
Offline Speech Recognition
We are going to focus on offline speech recognition systems here widely. Here are some methods that we’re going to demonstrate here.
1. Mozilla DeepSpeech
2. Arabic Speech Recognition with Klaam
3. Vosk-API (developed using the Kaldi project)
Let’s go through them one by one.
- DeepSpeech
Deepspeech is an open-source Speech-to-Text engine. It is the easiest way to do speech recognition using TensorFlow. Tensorflow is a huge platform for performing Artificial Intelligence, Machine Learning, and Deep Learning operations in various ways developed by Google. Before using DeepSpeech we have to make sure that TensorFlow is properly installed on your machine. DeepSpeech Documentation
Step 1: Creating a virtual environment
virtualenv -p python3 $HOME/tmp/deepspeech-venv/
source $HOME/tmp/deepspeech-venv/bin/activate
Step 2: Install Tensorflow
# Requires the latest pip
pip install –upgrade pip
# Current stable release for CPU and GPU
pip install tensorflow
Step 3: Install DeepSpeech
pip3 install deepspeech
If you want further support you can refer to Tesorflow Official Documentation
Step 4: Download English Model Files
curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech0.9.3-models.pbmm
curl -LO
https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deeps peech-0.9.3-models.scorer
Step 5: Download the Sample Audio file
curl -LO
https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/audio-0.9.3 .tar.gz
tar xvf audio-0.9.3.tar.gz
Step 6: Transcribe an audio
deepspeech –model deepspeech-0.9.3-models.pbmm –scorer deepspeech-0.9.3-models.scorer –audio audio/2830-3980-0043.wav
This is pretty simple because there’s a pre-trained model available for English speech recognition. But if you want to create speech recognition models for different languages, you can create your model. Check out the latest release including pre-trained models in GitHub by clicking here. You can check out what are the available languages datasets by clicking here. DeepSpeech mainly uses Common Voice Datasets for its training. For example, there are some models available that we can use. For Arabic, you can find these models here. Note that, some models are asking for CUDA devices which means your device must have a GPU.
- VOSK-API
VOSK-API VOSK is an offline speech recognition module that enables users to an easy way to do speech recognition in 20+ languages. VOSK modules are very simple and lightweight. It is a pre-build module that was created using the Kaldi project. Therefore, it is easy to deploy.
Also, VOSK gives us two types of models the small model and the large model. We can replace our model with a that we most want. According to VOSK documentation, most small models allow dynamic vocabulary reconfiguration. Big models are static the vocabulary cannot be modified in runtime. You can download models here. A small model typically is around 50Mb in size and requires about 300Mb of memory in runtime. Big models are for the high-accuracy transcription on the server. Big models require up to 16Gb in memory since they apply advanced AI algorithms.
Currently supporting the following platforms: Supported languages and dialects
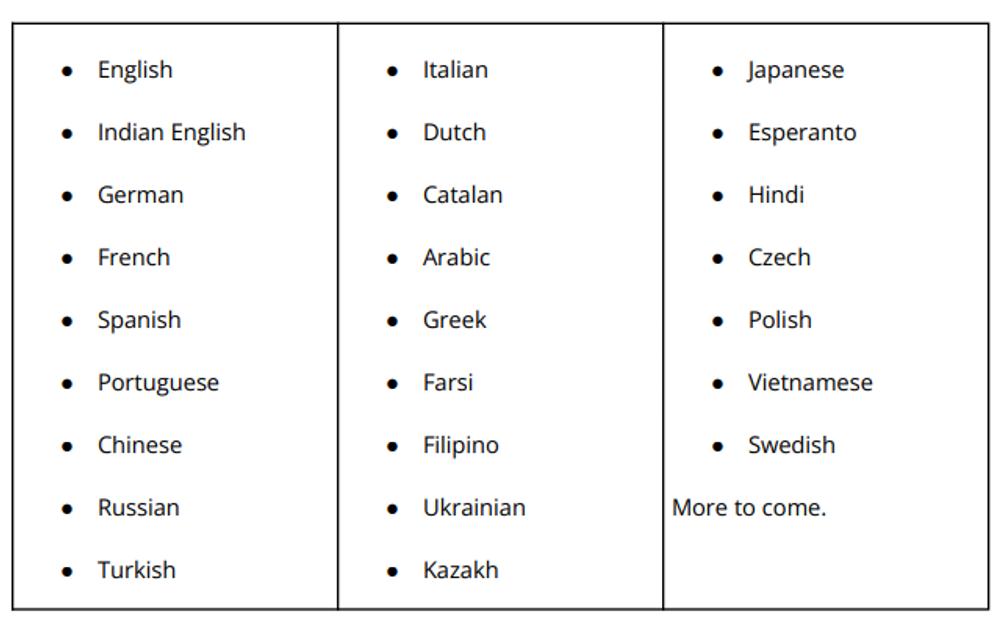
An Android Build, and an IOS BUILD and available for VOSK, but you have to contact authors by sending an email to mailto:contact@alphacephei.com
- Linux on x86_64
- Raspbian on Raspberry Pi 3/4
- Linux on arm64
- OSX (both x86 and M1)
- Windows x86 and 64
Please note that speech recognition tools didn’t give a perfectly accurate result. Sometimes it will give some unexpected results. However, the average accuracy of VOSK is very high.
Ok…! Let’s get started.
Step 1: Create the virtual environment and activate it
virtualenv venv
source venv/bin/activate

Step 2: Install python3 and pip3
As mentioned in the documentation make sure that, you have python 3.5 or above version installed. But highly recommend installing python 3.7 or above version when you trying to containerize your project. I faced lots of issues when using python 3.6. I was able to rectify those issues after starting with python 3.7.
python3 –version
pip3 –version

pip install vosk

Step 3: Install VOSK
pip install VOSK
Step 4: Clone the GitHub repository
git clone https://github.com/alphacep/vosk-api.git
This will clone the vosk-api repository from the GutHub and it will create a directory called “vosk-api”
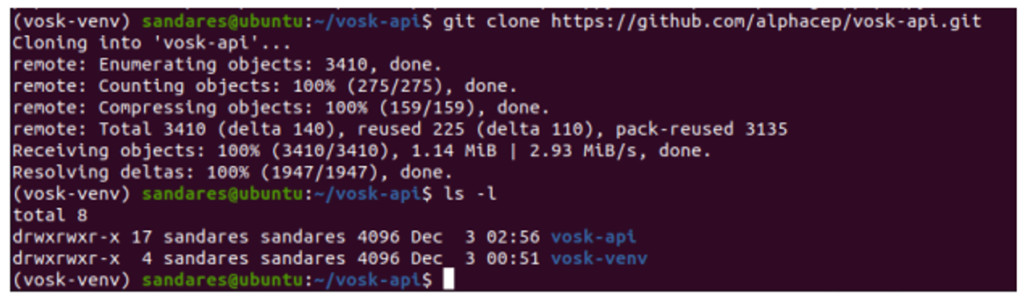
Then direct to vosk-api directory and there, you can see the following directory structure.
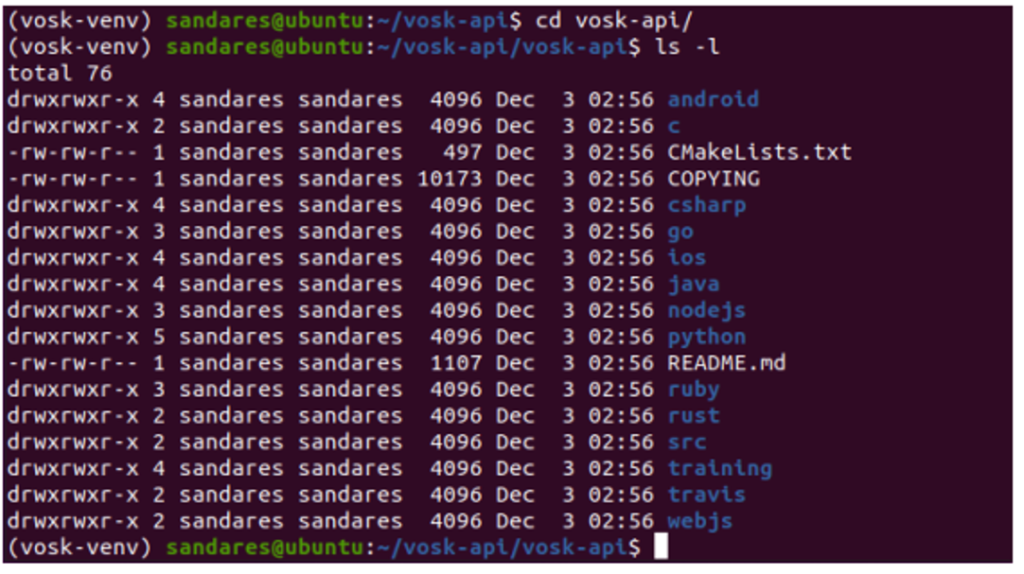
This contains modules that support Python, C, C#, Java, NodeJS, Ruby, etc. But here, we’re only talking about the python module.
Ok…! Now all set up.
Speech recognition using an audio file
First of all, direct to a directory called “python” and to the directory “example” and see what files we have in it.
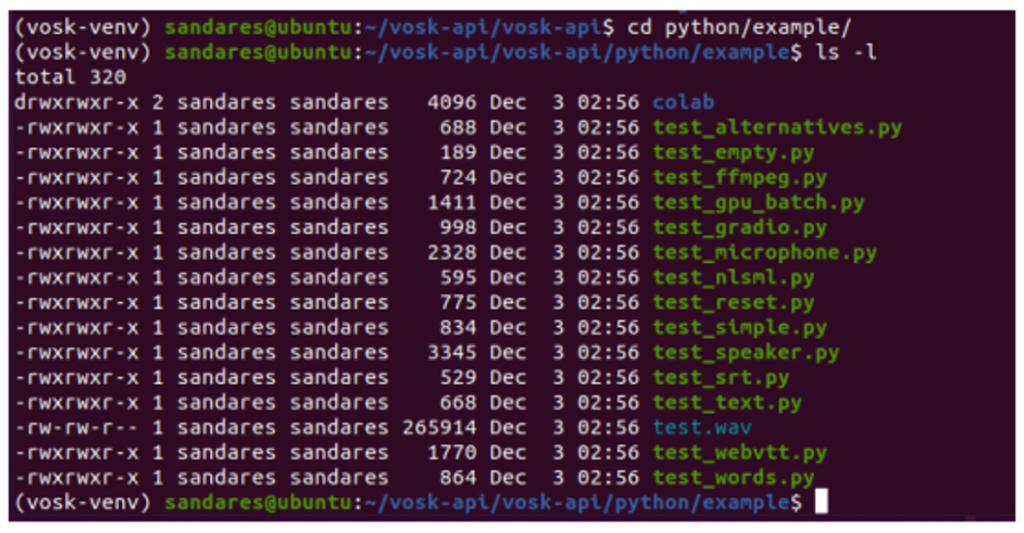
For this first example, I’m going to use the default test.wav file in the vosk project.
Note that, the first time that you run these commands, it will automatically download and set up the English small model by default.
- Process a .wav file as text.
Note that, when using your audio file make sure it has the correct format – PCM 16khz 16bit mono. Otherwise, if you have ffmpeg installed, you can use test_ffmpeg.py, which does the conversion for you.
This takes the audio file path as a command line argument. Simply run the following command and you can get the output.
python test_text.py test.wav
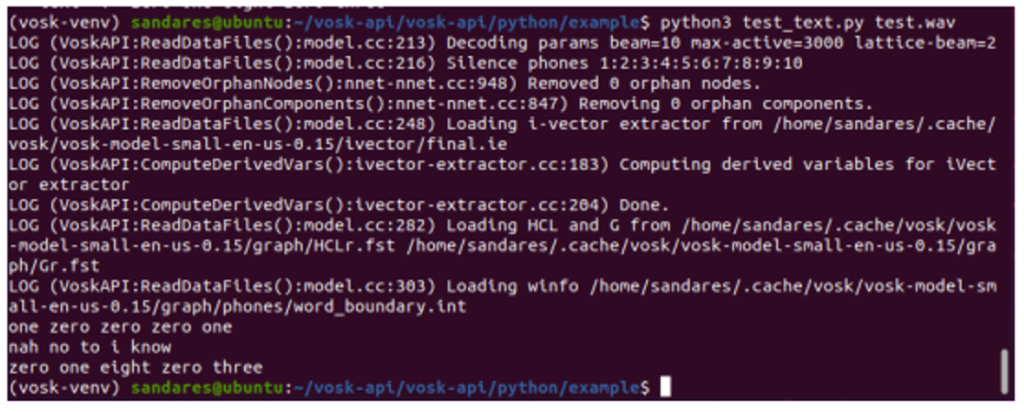
- Transcribe different types of audio files.
For transcribing different audio files we can use the python class called “test_ffmpeg.py”. This class requires to be installed FFmpeg in your environment. To install FFmpeg in your environment run the following commands.
sudo apt update
sudo apt install
ffmpeg ffmpeg -version
If you have different Linux environments try out these with their default package managers.
Then simply run the following command giving the audio file path as a command line argument.
python test_ffmpeg.py test.wav

To try out different types of audio files copy the audio files to this location and give the correct name as the command line argument. For example,
python test_ffmpeg.py test.mp4
python test_ffmpeg.py test.mp3
python test_ffmpeg.py test.ogg
I tried this with .mp4, .mp3, .ogg files and I got the same results as previous.
Replace the default model with another language model
First, download the model into your project. Here, I’ll choose the Arabic language and I’ll use a small Arabic model. If you want to use a large model; no worries, follow these steps as it is.
After downloading the model, unzip it and copy it to our project directory. (vosk-api/python/examples/). I renamed my model directory as “model-ar” for my convenience. Here is my project directory structure now.
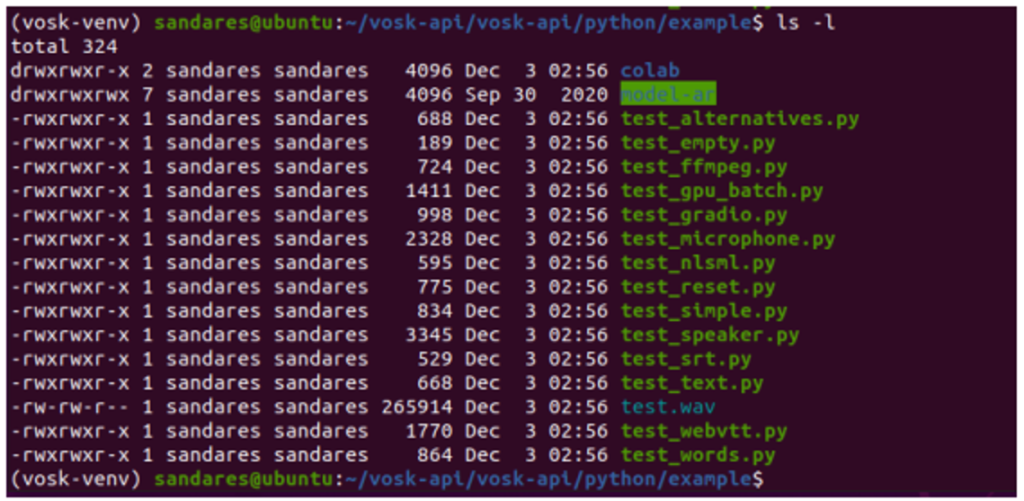
Now open our python class in a text editor.
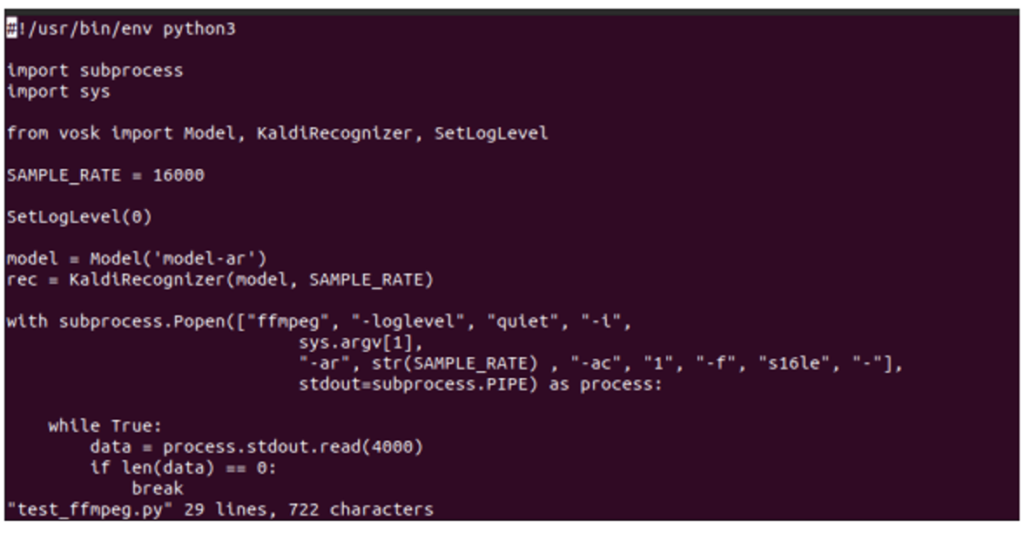
vi test_ffmpeg.py
Now you can see in the code, there’s a line “model = Model(lang=”en-us”)”. It gives a default argument as en-us when creating a “Model” object, saying that we are using an English model. Remove that parameter and give the path to our model directory as a String as follows and then, save it and quit.
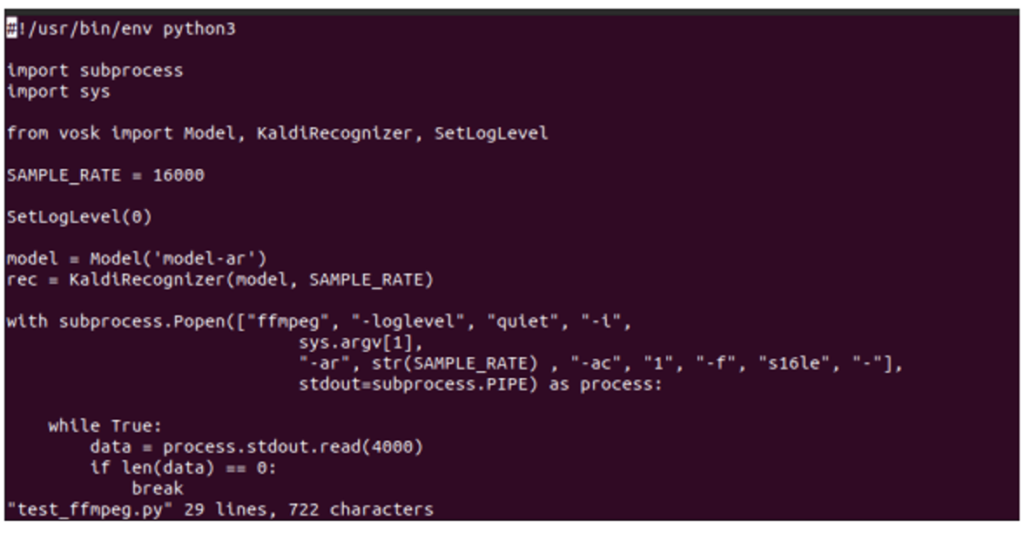
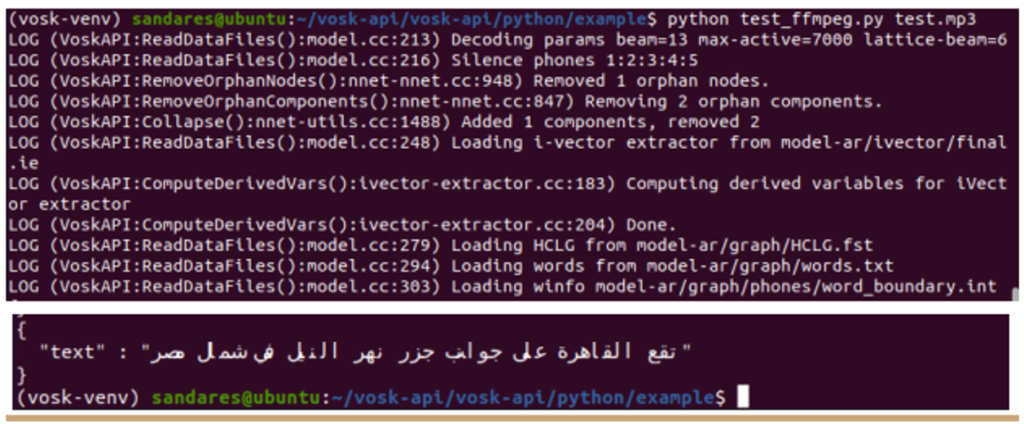
Then, run the following command and see the output. I have already placed an Arabic audio file as test.mp3 in my current directory.
python test_ffmpeg.py test.mp3
That’s it. Pretty cool. 🙂
Should I keep holding there all the files?
The answer is No. You can use files that only you need. Let’s take a look.
First, I’ll create a directory in a different location. (location: ../../../)
Then, redirect to the directory where our files are located. Then copy the following files to the newly-created directory.
- The Python file that you want. (for this example, text_ffmpeg.py)
- Model directory
- Audio file (test.mp3)
cp test_ffmpeg.py ../../../vosk-isolated/
cp -r model-ar/ ../../../vosk-isolated/
cp test.mp3 ../../../vosk-isolated/
Then locate to your new directory and see the directory structure.
These are the only things that you need. Then run again the following command and see the output.
python test_ffmpeg.py test.mp3
That’s very simple 🙂
Thank you for reading…!






